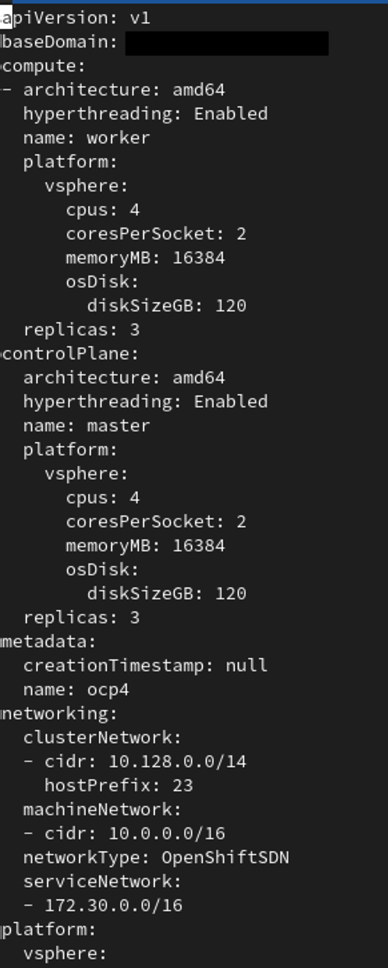
Let’s say that you deployed your OpenShift cluster with all the defaults using the installer provisioned infrastructure method. Not only that but you’ve got your some workloads already deployed but you want to adjust all the resources available to the underlying worker node VMs. How do you do that? I will detail those steps in this article!
You will need to figure out what the minimal worker node count that is needed to run your workloads. In this example we will use one but this will work if you have more. You could simply increase the replica count after adjusting the machineset instead.
First we will need to get the name of the machineset we will be altering.
oc get machinesets -n openshift-machine-apiThen we will scale the worker nodes to one replica in this example using the machineset name from the above command (ocp4-tkqrm-worker).
oc scale --replicas=1 ocp4-tkqrm-worker -n openshift-machine-apiNow let’s get the name of the worker node(s) that is/are left. We will use this later to delete those machines after we have edited our resources and scaled our cluster back up. Make sure to take the name of them down or run in a separate terminal to reference later when we remove them.
oc get nodesNow let’s edit our machineset resources to whatever we like using the following command.
oc edit machineset ocp4-tkqrm-worker -n openshift-machine-apiOnce you have edited the machineset we need to scale it back up. This will deploy all new worker nodes with the newly adjusted resource requirements. Note left over worker node resources will not change and this is why we need to delete them later in the tutorial.
oc scale --replicas=3 ocp4-tkqrm-worker -n openshift-machine-apiOnce the new machines are deployed and operational displaying the ready status using the oc get nodes command; we can delete the older worker nodes.
oc delete machine ocp4-tkqrm-worker-dzrvt -n openshift-machine-apiNote the above command will take a while to run while it drains the node of any pods that are running. Once the command completes, your cluster should have all new worker nodes with the newly specified resources!
-Mike