So you have your OpenShift 4.x cluster deployed, now it’s time to deploy some code. In this post I will describe how to get started deploying your code from private repos hosted on GitHub.
First let’s create a specific ssh key just for this use. If you have a linux system you can do this by running the following command.
ssh-keygen -t rsa -b 4096 -C "mike@example.com"This will generate your private and public key you will use for the project. Next we need to add the newly created public key to deploy keys section for the repo we want to deploy from at Github; you can do that by following the tutorial here.
Now that you have done this we need to add our private key to our OpenShift project to be able to run the code on our cluster. From your project click the Add option from the left hand menu. Then we want to choose From Git.

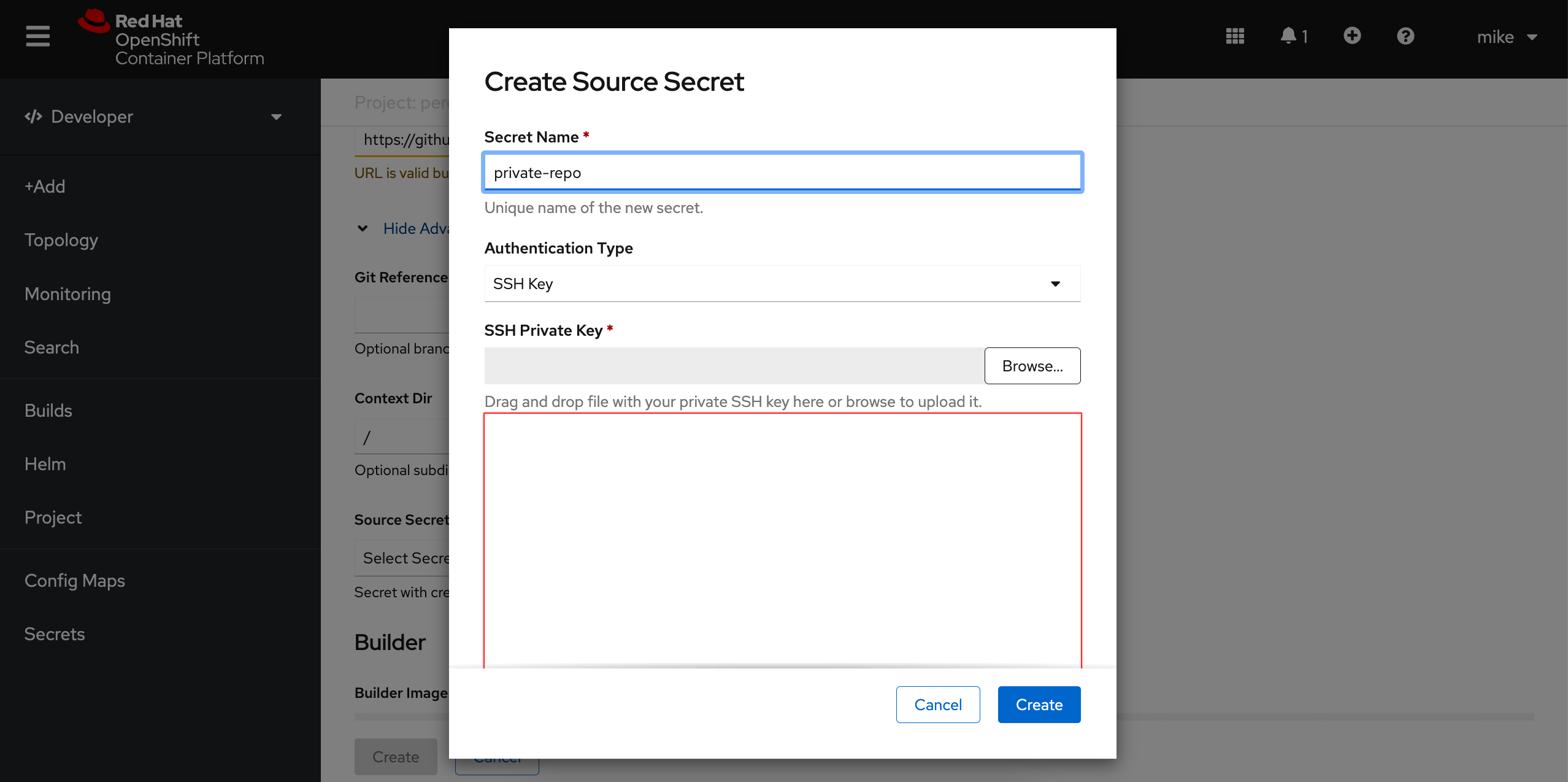
Next we will input our git project ssh url into the Git Repo URL field, followed by clicking the Show Advanced Git Options. Here we will need to add our private ssh key we generated earlier by clicking Select Secret Name followed by Create New Secret.

This will bring us to the screen where we want to add our private key to OpenShift as a new secret. We can do this by choosing SSH Key from the Authentication Type drop down menu and naming our new secret and pasting our ssh private key into the field and clicking create.
Select your builder image, name, and any advanced options and click Create. Your project should be deployed after a bit of time.
-Mike